问题
实验室的 L 同学最近在进行对多线程程序进行模糊测试的研究工作。在实验阶段,L 同学发现了一个有趣的现象:在使用著名的模糊测试工具 AFL 对一个多线程程序进行测试时,被测试程序的性能大约只有直接运行该程序的性能的 20% 左右。需要注意,直接运行的程序也经过 afl-gcc 处理,进行了覆盖率插桩。因此排除了是插桩的代码本身造成了性能下降的可能。我对这个有趣的问题进行了研究。在介绍结论前,我们需要先了解 AFL 这一模糊测试工具对被测试程序的插桩原理。
背景:AFL 的插桩机制
AFL 是一个灰盒模糊测试工具。“灰盒”意味着 AFL 会在运行被测试程序的同时收集被测试程序的代码覆盖率。AFL 使用“边覆盖率”这一指标作为被测程序的代码覆盖率,这里的“边”指程序中两个基本块之间的控制流转移边。AFL 提供了一个经过修改的编译器 afl-gcc,被测试程序需要使用 afl-gcc 进行编译后才能进行测试。afl-gcc 会在程序中的每个基本块的起始位置处插入一小段代码,这段代码在程序执行时会将程序控制流的上一条边的编号写入一块共享内存(以下称这块共享内存为 trace bitmap)中。在程序结束运行后,AFL 模糊测试器即可在这块共享内存中读取本轮测试的覆盖率信息。
问题分析
仔细分析已有条件,我们发现,由 afl-fuzz 调用程序和直接运行程序这两种运行方式造成的主要差别是前者会导致程序运行时读写 trace bitmap 中的数据。由于该程序是一个计算密集型程序,有大量的计算操作集中在程序的一小块代码区域,因此相对应地对 trace bitmap 中的一小块区域的读写也会非常频繁。该程序也是一个多线程程序,这意味着会有多个线程并发地密集读写 trace bitmap 中的一小块区域。由于 afl-gcc 插桩进被测程序的收集测试覆盖率的代码在读写 trace bitmap 时并不会使用锁进行同步,也不会使用原子读写指令,因此我们可以联想到这里的性能下降可能主要是由 CPU 缓存一致性协议造成的。
CPU 的缓存一致性协议
现代 CPU 执行一条指令往往只需要几个时钟周期。但是,从 RAM 中读取和写入数据则常常需要花费上百个时钟周期甚至更多。为缓解由于 CPU 速度和 RAM 速度之间巨大的差异而导致的性能下降问题,现代 CPU 在 CPU 核心和 RAM 之间都配备有缓存。如下图所示是常见的三级缓存的结构。
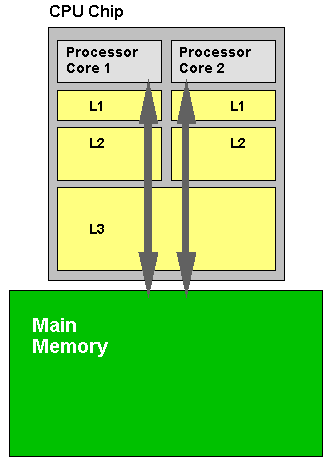
在这种常见的三级缓存结构中,每个 CPU 核心拥有自己的一级缓存(L1 cache)和二级缓存(L2 cache),但是三级缓存(L3 cache)是所有核心共享的。L1、L2 和 L3 的存储容量依次增加,但访问 L1、L2 和 L3 所需的时间也依次增加。当 CPU 需要读内存数据时,发起读请求的 CPU 核心会依次检查需要访问的地址所处的缓存行(Cache Line)是否已经存在于 L1、L2 和 L3 缓存中。如果是(即缓存命中),则 CPU 核心无需访问主存,只需要从相应的缓存中读取数据即可。在读数据结束后,CPU 往往会将读取的地址所处的缓存行放入 L1 缓存。因此,下一次再次读取该缓存行中的数据时,CPU 便可以从最快的 L1 缓存中读取数据。
真正的问题出现在当 CPU 需要向内存中写入数据时。当某个 CPU 核心需要向某个地址中写入数据时,如果这个地址所在的缓存行已经被其他 CPU 核心放入它们的 L1 或 L2 缓存,则某种机制必须介入以确保各个核心的私有缓存(即 L1 和 L2 缓存)中相同的缓存行内的数据是一致的。这种机制即是缓存一致性协议(Cache Coherence Protocol)。不同的 CPU 型号所使用的缓存一致性协议往往是不同的,Intel CPU 所使用的缓存一致性协议是 MESIF 缓存一致性协议。
缓存一致性协议是有性能代价的。即多个核心如果频繁向同一个缓存行写入数据,其总体执行速度将慢于多个核心频繁向不同的缓存行写入数据。为了了解缓存一致性协议对程序造成的性能影响,我们对 Intel CPU 上的缓存一致性协议进行了一个粗略的性能度量。
性能度量
用于性能度量的 CPU 型号为 Intel Core i9-10980XE @ 36x 4.7GHz。用于性能度量的源代码可以在 Github Gists 上找到。以下图表展示了我们的性能度量结果。
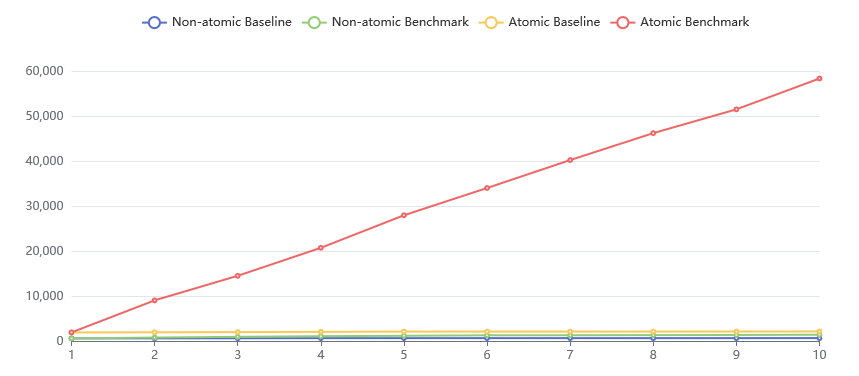
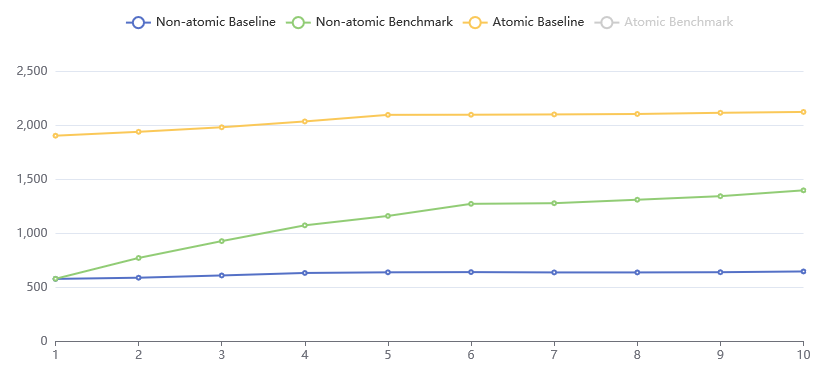
图表的横轴表示并发执行的线程数量,图表的纵轴表示性能度量程序执行完毕所消耗的 wall clock time,以毫秒计算。图表中展示了四种不同的配置,包括两个 baseline 以及两个 benchmark。它们的含义分别是:
- Non-atomic Baseline:每个线程以非原子递增的方式,递增一个
thread_local的计数器五亿次,并测量从所有线程开始到所有线程全部退出的时间; - Non-atomic Benchmark:每个线程以非原子递增的方式,递增一个全局的计数器五亿次,并测量从所有线程开始到所有线程全部退出的时间;
- Atomic Baseline:每个线程以原子递增的方式,递增一个
thread_local的计数器五亿次,并测量从所有线程开始到所有线程全部退出的时间; - Atomic Benchmark:每个线程以原子递增的方式,递增一个全局的计数器五亿次,并测量从所有线程开始到所有线程全部退出的时间。
结果分析
Non-Atomic Baseline & Benchmark
首先看 Non-atomic Baseline 的性能度量结果。与预期一致,随着线程数的增加,所有线程的总体执行时间并没有显著增加。这是因为各个线程分别读写不同的缓存行,缓存一致性协议几乎没有介入各个线程之间的缓存同步。
然后再看 Non-atomic Benchmark 的性能度量结果,可以看到与 Non-atomic Baseline 明显不同的运行时间变化趋势。随着线程数的增长,所有线程的总体执行时间也在增长。当线程数增加到 6 个线程时,non-atomic benchmark 所需的执行时间已经变成了 baseline 的两倍。这是因为各个线程读写的缓存行是相同的(都是全局计数器所在的缓存行),每当一个线程向计数器中写入一个新值时,缓存一致性协议都会介入,将新写入的值同步到其他线程的缓存中。
Atomic Baseline & Benchmark
在本次性能度量中,原子访问计数器是通过 std::atomic<uint64_t> 实现的。原子访问计数器时使用的是原子读写指令,在汇编上看则是一条带有 lock 前缀的内存读写指令。CPU 执行这条指令时会拉起内部的 LOCK# 信号,该信号的存在将确保同时最多只会有一个 CPU 核心正在读写内存。总体上看,使用原子读写指令访问内存比直接访问内存(Non-atomic Baseline)大约慢两倍左右(执行时间是三倍)。当所有线程分别读写自己独有的计数器时,随着线程数的增加,所有线程的总体运行时间也几乎没有增加,与 Non-atomic Baseline 的结果保持一致。当所有线程原子读写全局的计数器时,随着线程数的增加,所有线程执行完毕所需的时间则几乎以线性增长,且增长速度显著地快于 Non-atomic Benchmark 中的增长速度。为了分析这种现象的原因,我们需要观察 benchmark 程序的汇编代码:
AtomicBenchThreadEntry():
sub rsp, 8
movzx eax, BYTE PTR guard variable for AtomicBenchThreadEntry()::atomicCounter[rip]
test al, al
je .L20
.L12:
mov eax, 500000000
.L14:
lock add QWORD PTR _ZZL22AtomicBenchThreadEntryvE13atomicCounter[rip], 1
sub rax, 1
jne .L14
add rsp, 8
ret
.L20:
mov edi, OFFSET FLAT:guard variable for AtomicBenchThreadEntry()::atomicCounter
call __cxa_guard_acquire
test eax, eax
je .L12
mov edi, OFFSET FLAT:guard variable for AtomicBenchThreadEntry()::atomicCounter
call __cxa_guard_release
jmp .L12
.L20 基本块中是全局计数器的初始化代码,在此我们忽略。需要关注的是除 .L20 基本块以外的其他代码。
可以看到,循环变量被分配到寄存器 eax 中。在每一轮循环内,代码使用 lock add 指令对全局计数器进行原子递增 1 的操作。由于对存放循环变量的寄存器进行减法操作所需要的时间较少,在此可以忽略不计。因此可以认为线程运行的时间即为执行五亿次原子加法的时间。由于 lock 前缀的存在,且所有的线程均是对同一个地址进行原子加法操作,因此所有的线程的所有的原子加法操作在实际运行时是被序列化(Serialized)的。也就是说,没有两个原子加法操作能够被同时执行。因此,所有线程的总运行时间至少是每个线程运行时间的加和。因此 benchmark 运行的总时间随线程数的增长而线性增长。
结论
当程序中的多个线程密集地读写同一块缓存行中的数据时,缓存一致性协议能够对程序的性能带来显著的影响。在我们的测量中,当三个线程密集地读写同一块缓存行时,线程执行时间将增长 50%;当六个线程密集地读写同一块缓存行时,线程执行时间将增长 100%;当十个线程密集地读写同一块缓存行时,线程执行时间将增长 117%。综合实际情况,我们最终判定当使用 afl-fuzz 测试目标程序时,正是由于多个线程密集地访问 trace bitmap 中的一小块区域,导致了缓存一致性协议的频繁介入,最终导致了较为严重的性能下降。
可能的改进措施
针对前文提到的问题,我们提出了以下的一些改进措施,能够在一定程度上缓解测试时目标程序性能下降严重的问题:
1. 修改 AFL 的插桩机制,使得每个线程各自有独立的 trace bitmap。每个线程将分配和读写自己的 trace bitmap,并在线程结束运行时将自己的 trace bitmap 合并进通过共享内存共享给 afl-fuzz 的 primary trace bitmap。这样可以从根本上解决缓存一致性协议的性能开销问题,但是在实现上仍有许多困难。例如:
2. 可以适当降低 afl-gcc 的插桩密度(Instrumentation Density)。这会导致 afl-gcc 以某种指定的概率,选择性地插桩程序中的一部分基本块,而不是对所有的基本块都执行插桩。这样可以在一定程度上缓解缓存一致性协议的性能开销,但是同时也会降低覆盖率信息的精度。
3. AFL++ 支持用户自定义插桩区域以及收集覆盖率的区域。可以人工地选定适合的插桩区域和收集覆盖率的区域,以尽量避免缓存一致性协议的性能问题。